馬斯克力挺扎克伯格,OpenAI“0元”應(yīng)戰(zhàn)


扎克伯格預(yù)測(cè),Meta AI助手使用率幾個(gè)月后將超越ChatGPT。
7月24日凌晨,美國(guó)科技巨頭Meta推出迄今為止性能最強(qiáng)大的開源大模型——Llama 3.1 405B(4050億參數(shù)),同時(shí)發(fā)布了全新升級(jí)的Llama 3.1 70B和8B模型版本。
Llama 3.1 405B支持上下文長(zhǎng)度為128K tokens,是全球迄今為止性能最強(qiáng)大、參數(shù)規(guī)模最大的開源模型,在基于15萬億個(gè)tokens、超1.6萬個(gè)H100 GPU上進(jìn)行訓(xùn)練,這也是Meta有史以來第一個(gè)以這種規(guī)模進(jìn)行訓(xùn)練的Llama模型。
因性能佳、開源、多方合作,目前所有Llama模型版本的總下載量已經(jīng)超過3億次。研究人員基于超150個(gè)基準(zhǔn)測(cè)試集的評(píng)測(cè)結(jié)果顯示,Llama 3.1 405B可與GPT-4o、Claude 3.5 Sonnet和Gemini Ultra等業(yè)界頭部模型相媲美,包括亞馬遜AWS、英偉達(dá)、微軟Azure和谷歌云等25家頭部公司與Meta達(dá)成合作,引入Llama 3.1。
“這對(duì)于我們來說是久旱逢甘霖。”獨(dú)立分析師Jimmy告訴《中國(guó)企業(yè)家》。苦于缺乏長(zhǎng)期高質(zhì)量的訓(xùn)練數(shù)據(jù)已久,全球AI領(lǐng)域的開發(fā)人員終于迎來了開源曙光。一般來說,較小的專家模型(參數(shù)規(guī)模在10億~100億)通常利用“蒸餾技術(shù)”,也就是利用更大的模型來增強(qiáng)訓(xùn)練數(shù)據(jù)。但由于巨頭OpenAI的閉源,此類訓(xùn)練數(shù)據(jù)的缺乏是各大模型共同的難題。
開、閉源之爭(zhēng)一直是AI圈的中心話題。Meta創(chuàng)始人、CEO扎克伯格提到:“我相信Llama 3.1的發(fā)布將成為行業(yè)的一個(gè)轉(zhuǎn)折點(diǎn)”;360集團(tuán)創(chuàng)始人周鴻祎也曾表示,開源社區(qū)聚集全球上千家公司、數(shù)十萬程序員和工程師,開發(fā)力量是一個(gè)閉源公司的數(shù)百倍。
扎克伯格開源Llama 3.1,逼急O(jiān)penAI
Meta公布前一天,Llama 3.1的模型和基準(zhǔn)測(cè)試結(jié)果已經(jīng)在國(guó)外的Reddit等社區(qū)上泄露,Llama 3.1的磁力鏈接也被流傳,“強(qiáng)大”“開源”成為評(píng)論區(qū)的高頻詞。
Llama 3.1包含8B、70B和405B三種參數(shù)規(guī)模,其中超大杯4050億版本,該系列模型上下文窗口增加到了128K,擴(kuò)大16倍;增加了8種支持語言;提升了工具使用能力,支持搜索和Wolfram Alpha的數(shù)學(xué)推理;擁有更寬松的許可,允許使用模型輸出改進(jìn)其他LLMs。
事實(shí)上,開、閉源的大模型差距正在縮小。Meta在官博指出最新一代的Llama將激發(fā)新的應(yīng)用程序和建模范式,包括利用合成數(shù)據(jù)生成來提升和訓(xùn)練更小的模型,以及模型蒸餾——這是一種在開源領(lǐng)域從未有過的能力。在基準(zhǔn)測(cè)試集中的表現(xiàn)幾乎可以媲美當(dāng)前頂尖閉源模型GPT-4o和Claude 3.5 Sonnet,并且所有版本都可以在官網(wǎng)下載使用。
Meta對(duì)Llama 3.1的布局在今年4月就有跡可循。當(dāng)時(shí)Meta就透露說,正在開發(fā)人工智能行業(yè)的第一款產(chǎn)品:一個(gè)性能與OpenAI等公司最好的私有模型相媲美的開源模型。
相比于OpenAI對(duì)技術(shù)細(xì)節(jié)的“惜字如金”,Meta此次不僅開放小助手應(yīng)用在線試玩,還發(fā)布了近100頁(yè)的詳細(xì)論文,涵蓋了創(chuàng)造Llama 3.1過程中的一切,比如訓(xùn)練數(shù)據(jù)、過濾、退火、合成數(shù)據(jù),并透露Llama 4已在開發(fā)中。
扎克伯格親自為開源大模型Llama 3.1站臺(tái),在推特撰寫長(zhǎng)文《Open Source AI Is the Path Forward》強(qiáng)調(diào)開源的意義,他表示:“今天我們正邁出下一步——使開源AI成為行業(yè)標(biāo)準(zhǔn)。”在特斯拉前AI總監(jiān)關(guān)于Llama 3.1大模型的帖子下面,馬斯克罕見地盛贊扎克伯格:“這令人印象深刻,扎克(伯格)的開源決定確實(shí)值得贊揚(yáng)。”
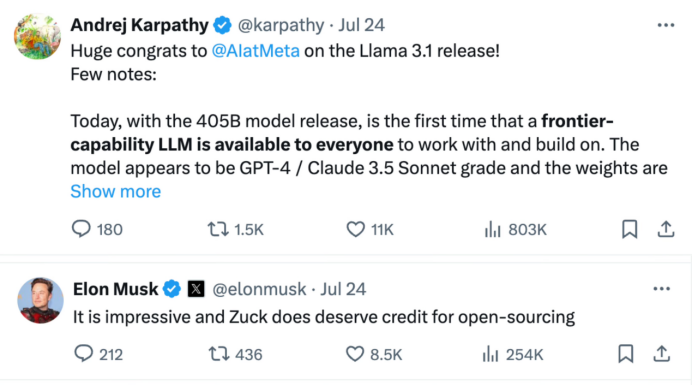 來源:馬斯克回復(fù)推特截圖
來源:馬斯克回復(fù)推特截圖
Meta與OpenAI分別代表著開源與閉源的兩條技術(shù)路線。關(guān)于開源和閉源的斗爭(zhēng)由來已久,此前在彭博社的采訪中,扎克伯格更是公開嘲諷:“阿爾特曼的領(lǐng)導(dǎo)能力值得稱贊,但有點(diǎn)諷刺的是公司名為OpenAl卻成為構(gòu)建封閉式人工智能模型的領(lǐng)導(dǎo)者。”
面對(duì)Meta這次的大招,OpenAI以低價(jià)策略應(yīng)戰(zhàn)。
Meta公布Llama 3.1兩個(gè)多小時(shí)后,OpenAI發(fā)布消息:公司推出了GPT-4o mini微調(diào)功能版,從現(xiàn)在到9月23日可免費(fèi)使用。據(jù)了解,GPT-4o mini的輸入tokens費(fèi)用比GPT-3.5 Turbo 低90%,輸出tokens 費(fèi)用低80%。即使免費(fèi)期結(jié)束,GPT-4o mini的價(jià)格也比GPT-3.5 Turbo低一半。
價(jià)錢打折,但產(chǎn)品能力不打折。據(jù)了解,GPT-4o mini比經(jīng)典版本GPT-3.5 Turbo能力更強(qiáng),GPT-4o mini的上下文長(zhǎng)度為65k tokens,是GPT-3.5 Turbo的四倍,推理上下文長(zhǎng)度為128k tokens,是GPT-3.5 Turbo的八倍。
這就意味著,若使用GPT-4o mini微調(diào)版,就可以享受:以實(shí)惠的使用費(fèi)用,使用更長(zhǎng)的上下文、更聰明的頂尖大模型。阿爾特曼更是在推特發(fā)文表示,GPT-4o mini以1/20的價(jià)格在lmsys上實(shí)現(xiàn)了與GPT-4o接近的性能表現(xiàn),他還希望大家能夠多多使用GPT-4o mini 微調(diào)版本。
此次OpenAI以發(fā)布GPT-4o mini 微調(diào)版為盾,不僅是對(duì)Meta開源大模型步步緊逼的反擊,也同時(shí)將硅谷AI價(jià)格戰(zhàn)的火藥味推得更濃。
用價(jià)格“圍剿”O(jiān)penAI
即使OpenAI推出可免費(fèi)使用的小模型,但比起同為大模型的產(chǎn)品,Llama 3.1 405B的價(jià)格比GPT-4o仍然要低很多。
公開數(shù)據(jù)顯示,Llama 3.1的價(jià)格在Fireworks平臺(tái)上是每1百萬tokens的輸入/輸出價(jià)格是3美元,而GPT-4o每1百萬tokens的輸入價(jià)格是5美元,輸出價(jià)格是15美元。此外,Claude 3.5 sonnet的每1百萬tokens的輸入價(jià)格是3美元,輸出價(jià)格是15美元。
這不是硅谷在AI方面的第一次“價(jià)格戰(zhàn)”。
今年5月,OpenAI發(fā)布GPT-4o并支持免費(fèi)試用,調(diào)用API的價(jià)格也比GPT-4-Turbo降低一半——打響了硅谷大模型價(jià)格戰(zhàn)第一槍,同時(shí)這也是2023年起OpenAI的第4次降價(jià)。7月18日深夜,GPT-4o mini的正式亮相,與GPT-3.5相比性能更強(qiáng),也更便宜,連阿爾特曼都曾建議大家不要再用GPT-3.5了。
用低價(jià)“圍剿”O(jiān)penAI已成大模型公司們的慣例。公開信息顯示,與GPT-4o相比較,各大公司的最新發(fā)布的產(chǎn)品分別是:Meta的Llama 3.1,谷歌的Gemini 1.5 pro,Claude 3 Sonnet,新近的Mistral AI,這些最新大模型價(jià)格均低于GPT-4o。
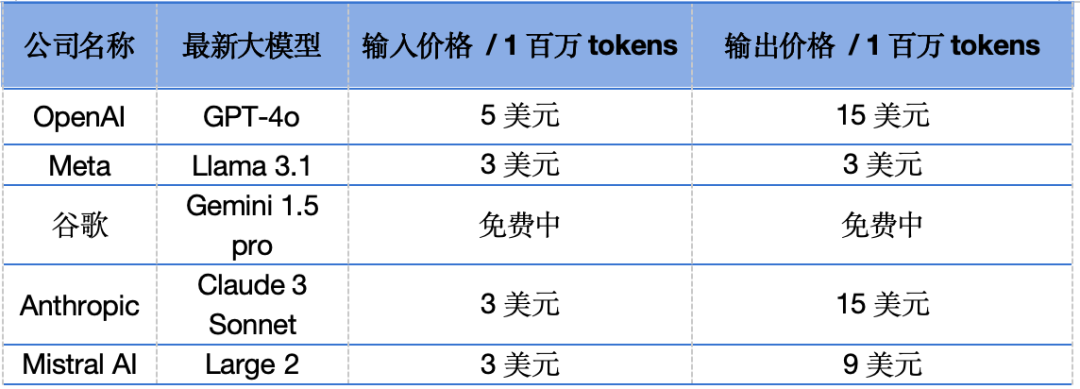 國(guó)際頭部大模型公司產(chǎn)品價(jià)格表,信息來源各大模型官網(wǎng)。制表:孫欣
國(guó)際頭部大模型公司產(chǎn)品價(jià)格表,信息來源各大模型官網(wǎng)。制表:孫欣
而大模型的價(jià)格戰(zhàn)在國(guó)內(nèi)也已開始。5月6日,初創(chuàng)大模型公司DeepSeek深度求索將輸入價(jià)格定為1元/百萬tokens。緊接著智譜AI的GLM-3-Turbo模型、字節(jié)跳動(dòng)的豆包大模型,以及阿里巴巴的通義系列模型、百度的文心一言模型紛紛跟牌。
低價(jià),正在成為一種趨勢(shì)。
小模型或?qū)⒊蔀锳I新風(fēng)口
一直以來,大模型的發(fā)展受困于成本。斯坦福HAI研究所發(fā)布的《斯坦福2024年人工智能指數(shù)報(bào)告》指出,AI模型的培訓(xùn)成本已經(jīng)達(dá)到了前所未有的水平。例如,OpenAI的GPT-4估計(jì)使用了7800萬美元用于計(jì)算訓(xùn)練,而谷歌的Gemini Ultra花費(fèi)了1.91億美元用于計(jì)算。2017年訓(xùn)練最初的Transformer模型的成本僅為約900美元。
而現(xiàn)在,小模型成了AI公司們降本增效的利器。
掀起新一輪價(jià)格戰(zhàn)前,OpenAI先手開卷小模型。7月18日,OpenAI發(fā)布小模型GPT-4o mini,并稱其為“迄今為止最具成本效益的小模型”,正是上周(北京時(shí)間7月25日凌晨)宣布免費(fèi)使用的GPT-4o mini微調(diào)版的真身;蘋果公司在Hugging Face上發(fā)布了DCLM-7B開源小模型;不久后,英偉達(dá)和法國(guó)明星AI獨(dú)角獸Mistral聯(lián)合發(fā)布了名為Mistral NeMo的小模型,稱可以直接替換任何使用Mistral 7B的系統(tǒng)。
小模型,通俗來說就是比大模型處理數(shù)據(jù)能力略小的模型,可以理解為mini版的大模型。在AI領(lǐng)域,參數(shù)規(guī)模越大,大模型學(xué)習(xí)能力越強(qiáng),諸如GPT-4這些模型通常擁有數(shù)十億甚至數(shù)百億的參數(shù)。然而據(jù)OpenAI介紹,小模型GPT-4o mini在MMLU上的得分為82%,甚至某些表現(xiàn)優(yōu)于大模型GPT-4。
對(duì)大部分用戶來說,小模型是大模型的“平替”,極具性價(jià)比。盡管小模型在處理復(fù)雜任務(wù)上不具優(yōu)勢(shì),但在小任務(wù)上具備更快的推理能力。同時(shí)對(duì)計(jì)算機(jī)存儲(chǔ)需求也更小,耗能也更小。根據(jù)各公司的大、小模型產(chǎn)品對(duì)比來看,小模型價(jià)格較低。根據(jù)Artificial Analysis的統(tǒng)計(jì),美國(guó)AI公司主流“小模型”中,GPT-4o mini的價(jià)格最低,在無需處理復(fù)雜任務(wù)的“普通用戶”中或許將更受歡迎。
低價(jià)來自成本的降低。阿爾特曼在推特上發(fā)文指出,2022年世界上最好的模型text-davinci-003,它比GPT-4o mini差得多,但成本要貴上100多倍。這一波OpenAI搶先布局小模型,就是想通過顯著降低AI使用成本,擴(kuò)大AI使用范圍。
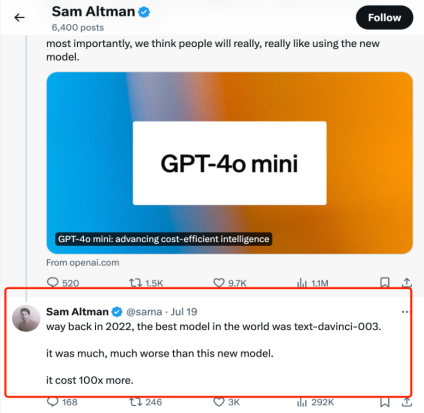
來源:阿爾特曼推特截圖
低成本、低性價(jià)比、更廣用戶適配度,小模型不僅能成為AI公司們to C端的有力手段,更是AI價(jià)格戰(zhàn)的應(yīng)對(duì)神器,或?qū)⒊蔀橄乱粋€(gè)新風(fēng)口。
今年年初,2024百度AI開發(fā)者大會(huì)上,李彥宏提出未來大型的AI原生應(yīng)用都是大小模型的混用。他還表示,用戶基于百度文心4.0,可以靈活剪裁出適用于不同場(chǎng)景的小尺寸模型,“在一些特定場(chǎng)景中,經(jīng)過精調(diào)后的小模型,其使用效果甚至可以媲美大模型。”
國(guó)外GPT-4o、Llama 3.1輪番轟炸,國(guó)內(nèi)“千模大戰(zhàn)”大浪淘沙,無論開源還是閉源,高價(jià)還是低價(jià)、大模型還是小模型,這波AI浪潮最后的勝者還未顯現(xiàn)。
參考資料:
扎克伯格《Open Source AI is the Path Forward》,原文鏈接:https://www.facebook.com/zuck
Meta《Meta Large Language Model Compiler: Foundation Models of Compiler Optimization》,原文鏈接:https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/
《硅谷AI保衛(wèi)戰(zhàn)打響!最強(qiáng)4050億開源模型Llama 3.1上線,OpenAI:GPT-4o mini免費(fèi)用》,鈦媒體
本文鏈接:http://m.albanygandhi.com/news-23-463.html馬斯克力挺扎克伯格,OpenAI“0元”應(yīng)戰(zhàn)
聲明:本網(wǎng)頁(yè)內(nèi)容由互聯(lián)網(wǎng)博主自發(fā)貢獻(xiàn),不代表本站觀點(diǎn),本站不承擔(dān)任何法律責(zé)任。天上不會(huì)到餡餅,請(qǐng)大家謹(jǐn)防詐騙!若有侵權(quán)等問題請(qǐng)及時(shí)與本網(wǎng)聯(lián)系,我們將在第一時(shí)間刪除處理。
中共北京市委 北京市人民政府關(guān)于北京市全面優(yōu)化營(yíng)商環(huán)境打造“北京服務(wù)”的意見
關(guān)于發(fā)展銀發(fā)經(jīng)濟(jì)增進(jìn)老年人福祉的意見
【解讀】金融監(jiān)管總局有關(guān)負(fù)責(zé)人就《國(guó)務(wù)院關(guān)于推進(jìn)普惠金融高質(zhì)量發(fā)展的實(shí)施意見》答記者問
【解讀】關(guān)于《海淀區(qū)積極應(yīng)對(duì)疫情影響助企紓困的若干措施》的政策解讀
我國(guó)昆蟲學(xué)科技論文數(shù)量世界第一
“仲華”熱物理試驗(yàn)裝置又有兩大中心開工
首批30家服務(wù)站“各顯其能”—— 北京:多維度靶向賦能專精特新企業(yè)
2023年粵港澳大灣區(qū)高價(jià)值專利培育布局大賽收官
2023年度科技部《政府網(wǎng)站監(jiān)管年度報(bào)表》
“創(chuàng)客北京2024”創(chuàng)新創(chuàng)業(yè)大賽 龍?jiān)喘h(huán)保?退役新能源裝備資源化專項(xiàng)賽 項(xiàng)目征集通知
奮發(fā)圖強(qiáng):DY月付額度怎么提現(xiàn)出來,9種辦法教你簡(jiǎn)單操作流程
國(guó)內(nèi)購(gòu)買厄達(dá)替尼多少錢一盒yb價(jià)格一覽表!4mg56粒印度厄達(dá)替尼價(jià)格折合人民幣4200元一盒
大吉大利:廣州增城區(qū)代還信用卡最好還款服務(wù),實(shí)體店多種方式
立志成才:羊小咩額度怎么提現(xiàn)出來,試試這五個(gè)操作方法
奮發(fā)圖強(qiáng):羊小咩額度怎么套出來的?-?推薦十個(gè)操作流程
如登春臺(tái):青島平度市代還信用卡墊還,可長(zhǎng)期合作,值得信任
悅刻五代多少錢一支,悅刻一代桿子多少錢
全神貫注:DY月付怎么套出來(試試十個(gè)提現(xiàn)方法)
方法:套京東白條怎么找商家(最完美實(shí)用的6種變現(xiàn)技巧)-知者
親測(cè)讀懂:支付寶花唄怎么提現(xiàn)出來(手把手教你三個(gè)方法)






